Graph Neural Networks (GNNs) have advanced graph structure understanding via recursive information exchange and aggregation among graph nodes. To improve model robustness, self-supervised learning (SSL) has emerged as a promising approach for data augmentation. However, existing methods for generating pre-trained graph embeddings often rely on fine-tuning with specific downstream task labels, which limits their usability in scenarios where labeled data is scarce or unavailable. To address this, our research focuses on advancing the generalization capabilities of graph models in challenging zero-shot learning scenarios. Inspired by the success of large language models (LLMs), we aim to develop a graph-oriented LLM that can achieve high generalization across diverse downstream datasets and tasks, even without any information available from the downstream graph data. In this work, we present the GraphGPT framework that aligns LLMs with graph structural knowledge with a graph instruction tuning paradigm. Our framework incorporates a text-graph grounding component to establish a connection between textual information and graph structures. Additionally, we propose a dual-stage instruction tuning paradigm, accompanied by a lightweight graph-text alignment projector. This paradigm explores self-supervised graph structural signals and task-specific graph instructions, to guide LLMs in understanding complex graph structures and improving their adaptability across different downstream tasks. Our framework is evaluated on supervised and zero-shot graph learning tasks, demonstrating superior generalization and outperforming state-of-the-art baselines.
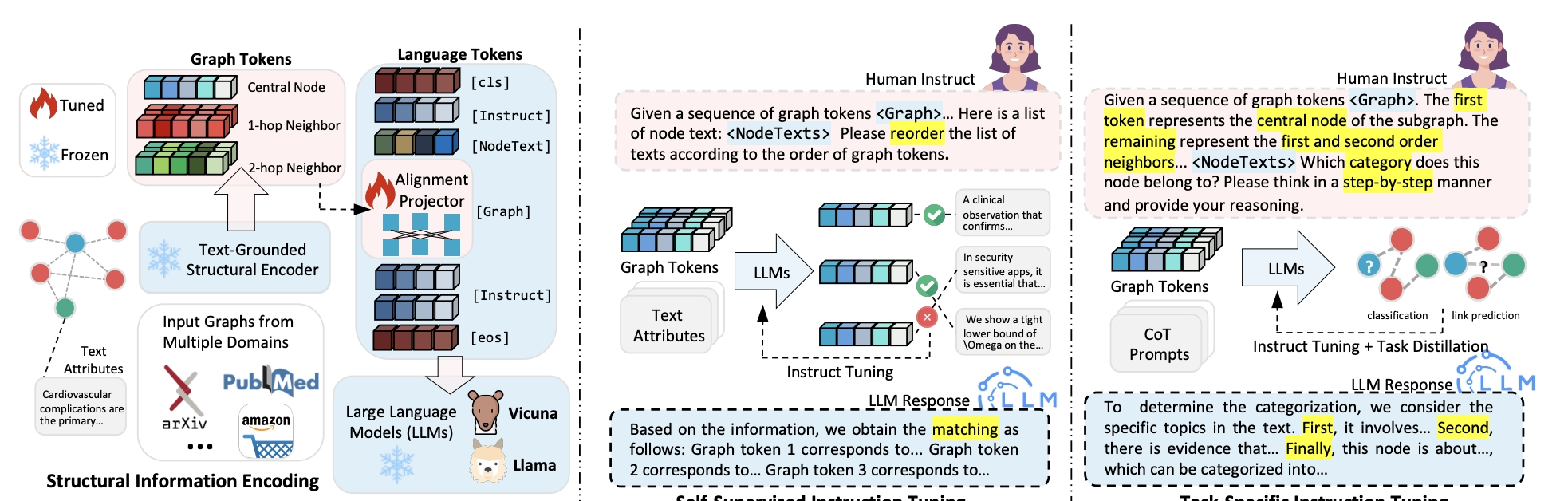
Figure 1: The overall architecture of our proposed GraphGPT with graph instruction tuning paradigm.
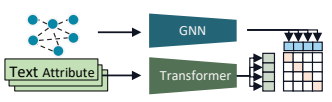
Figure 2: Workflow of text-structure alignment.
We adopt a similar instruction template, which consists of three parts. To generate graph information for each node, we employ the same neighbor sampling approach used in the first stage. This approach ensures that relevant graph information is captured, with each node acting as the central node. For the node classification task, the human question instruction contains both the indicator token

Figure 3: Our instruction designs for graph matching task (upper), node classification (middle) and link prediction (lower).
We conduct experiments on the node classification task, evaluating both supervised and zero-shot scenarios. The overall performance is presented in Table 1. Supervised Task Settings: We train the models on a specific dataset and evaluated their performance on the corresponding test set (e.g., training on Arxiv-Arxiv and testing on the Arxiv test set). Zero-Shot Task Settings: We train the models on a specific dataset and test them on other datasets without any additional training (e.g., training on Arxiv-PubMed and testing on the PubMed dataset). To account for variations in the number of classes across different datasets, we employed a classifier trained with transfer data, typically a linear layer, when testing GNN-based models. In Table 1, "-7B-" represents the parameter scale, while "-v1.1-" and "-v1.5-" indicate different versions of the base Vicuna model. "-stage2" indicates that only the second stage tuning is adopted. "-std" and "-cot" denote the use of the standard and generated COT instruction datasets, respectively.
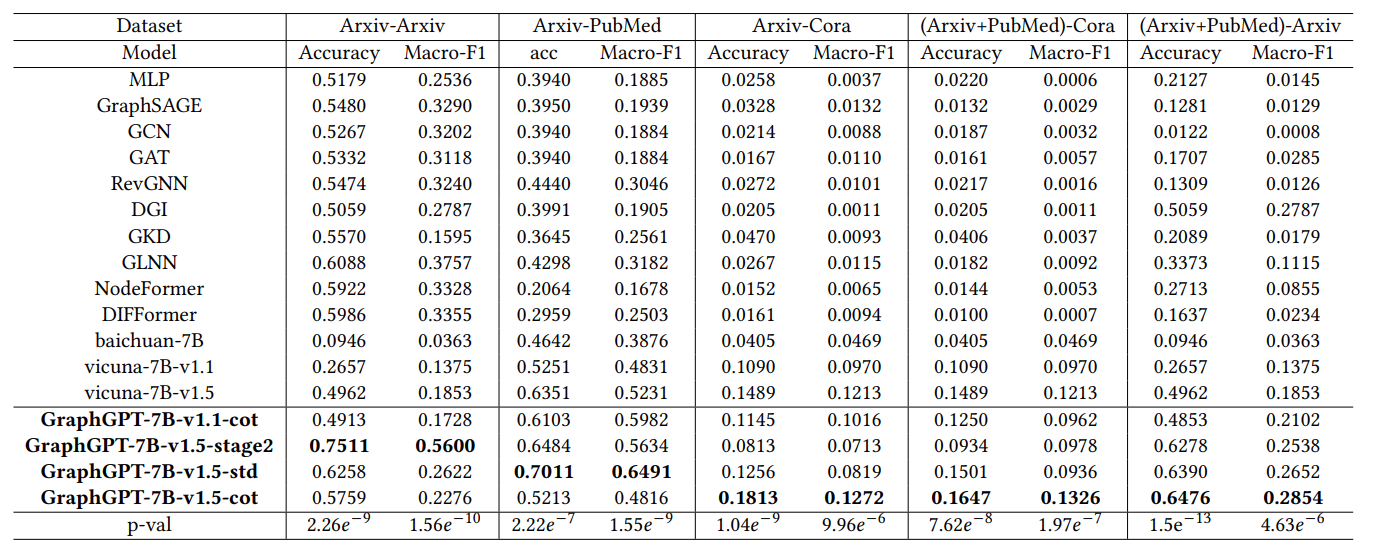
Figure 4: Performance comparison of various methods on node classification under both supervised and zero-shot settings.
we explore the generalization ability of our model by incorporating more instruction data to fine-tune the LLM for effectively handling various types of tasks.
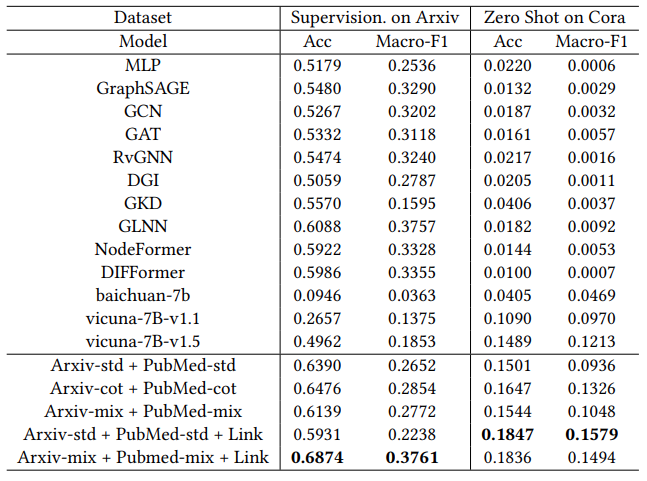
Figure 5: Performance comparison of various instruction mixtures in supervised learning on the Arxiv dataset and the zero-shot setting on the Cora dataset for node classification.
We conduct an ablation study to investigate the individual contributions of different sub-modules of our proposed framework, and the results are reported in Table 4.
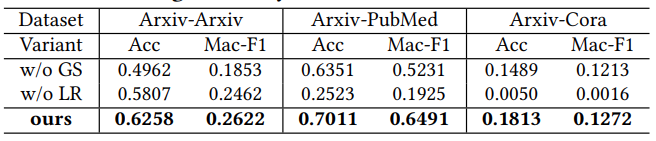
Figure 6: Module ablation study under both supervised and zero-shot settings to analyze the individual contributions.
Study on the time and space efficiency of our GraphGPT during both the training and inference stages.
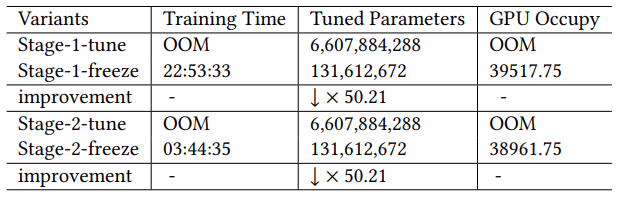
Figure 7: Study on the time and space efficiency of our GraphGPT during both the training and inference stages.
The study aims to assess the computational efficiency of our model during both the model training and inference stages.
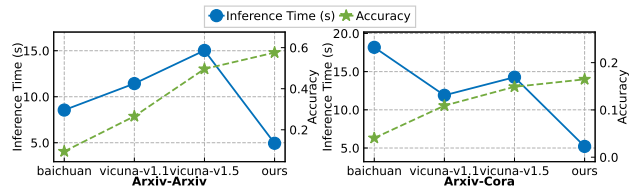
Figure 8: Inference efficiency study of our GraphGPT Training Efficiency with Graph Instruction Tuning.
@articles{tang2023graphgpt,
title={GraphGPT: Graph Instruction Tuning for Large Language Models},
author={Jiabin Tang and Yuhao Yang and Wei Wei and Lei Shi and Lixin Su and Suqi Cheng and Dawei Yin and Chao Huang},
year={2023},
eprint={2310.13023},
archivePrefix={arXiv},
primaryClass={cs.CL}
}